o11y-weekly
monotonicity demo
TL;DR
Rates are essential to support monitoring and alterting while long lived cumulative counters can be useful for business KPI and can be approximated (approximated resolution for cumulative model) or partially exact (data loss for delta model).
The cumulative model trade-offs are not really compatible to support exact counters due to non monotonic issue and data loss.
This demo illustrates those trade-offs for observability.
Context
Run the docker compose demo with prometheus and an app to increment a counter.
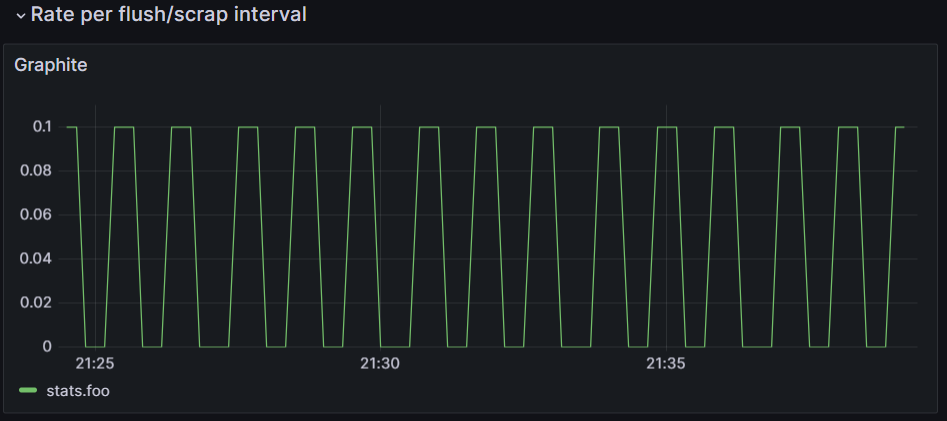
Every 10s (prometheus scrap interval, statsd and otlp flush) , the metric is scrapped and a counter increases by 1 each time.
Every 30s, the app is stopped for 30s and restarts.
The counter increases by 3 per minute which is (30s / 10s) and the rate should be between from 0 to 0.1rps.
This demo emphasises the restart and reset/state management issue on pull + cumulative based metrics.
1/ Clone the repo https://github.com/o11y-weekly/o11y-weekly.github.io/tree/main/2023-11-09_Monotonicity/demo
2/ Run docker compose
./run.sh
3/ Open in a brower the grafana graphs
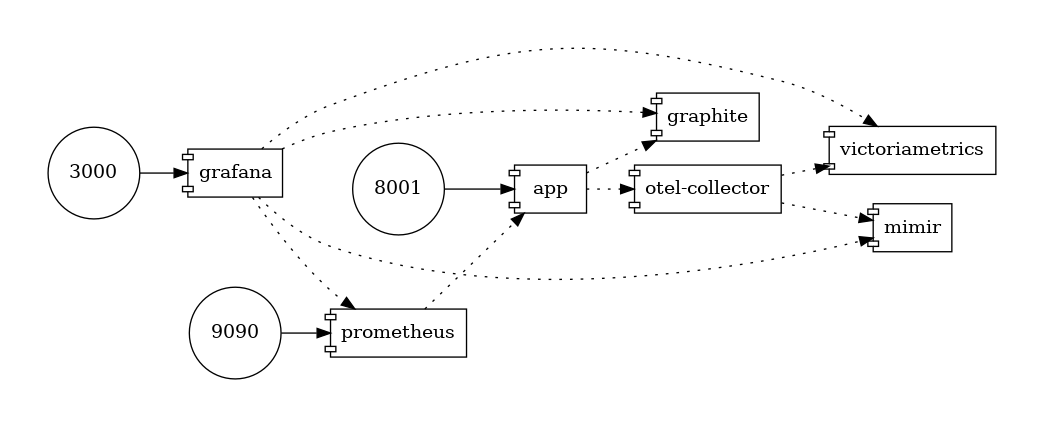
Architecture
- app : a rust app which sends metrics with statsd / prometheus and otlp specs. A webserver serves prometheus metrics.
- prometheus : scraps every 10s the app which increases app counter
- OpenTelemetry Collector contrib collector receives otlp metrics from the app and sends it to mimir and victoriametrics
- Grafana and Prometheus are used as a data visualization webserver.
- Cumulative backends : VictoriaMetrics (with prometheus datasource), Prometheus, Mimir.
- Delta backends : graphite.
To properly see differences between graphite/prometheus/victoriametrics/mirmir, Grafana is used to visualize datapoints.
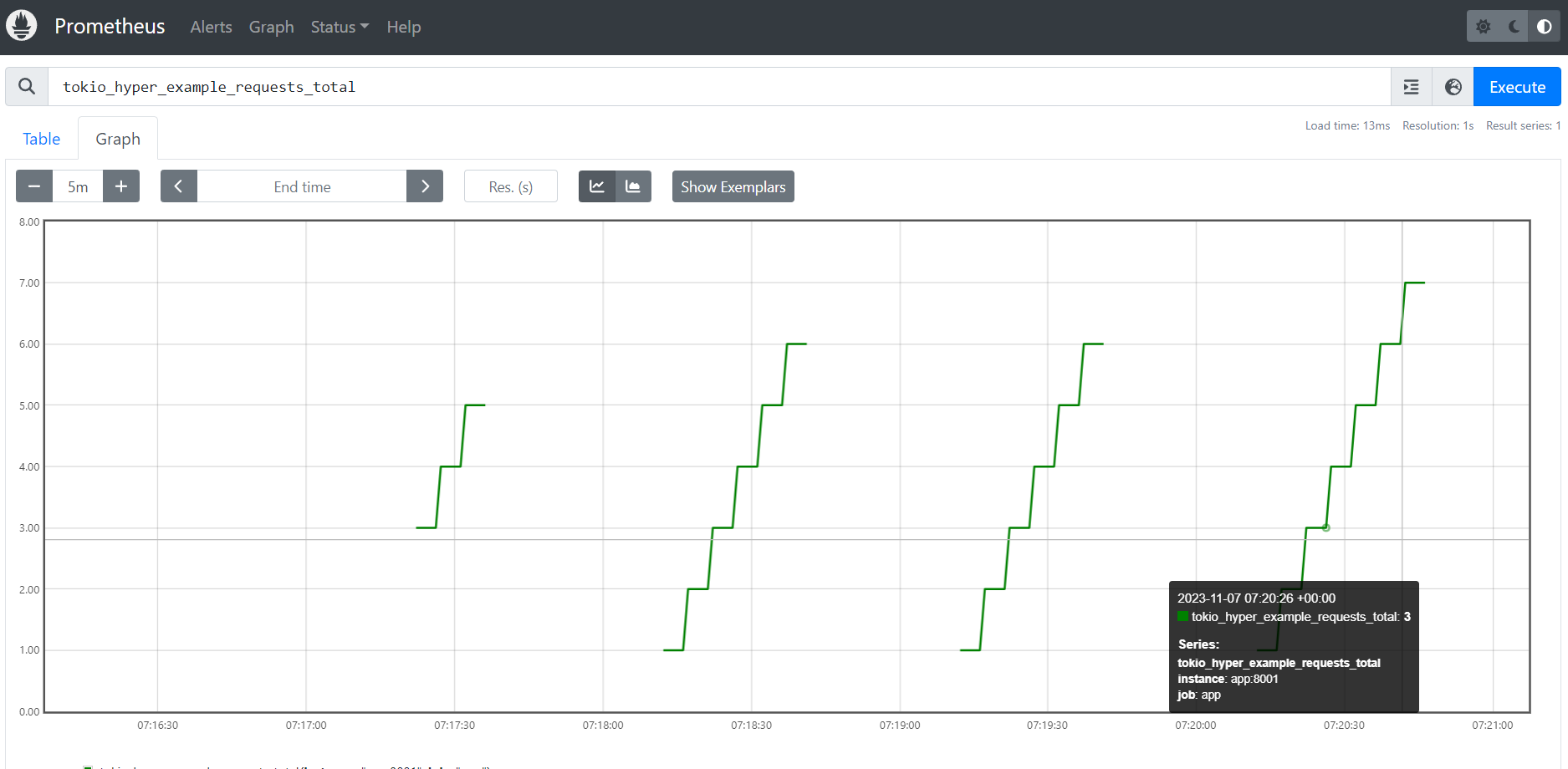
Prometheus datapoint visualization
Instant Vector
As soon as the app restarts, the counter is no more monotonic on reset.
Range Vector increase
Viewing a 1mn range of the metrics is better but the counter looks weird due to resets.
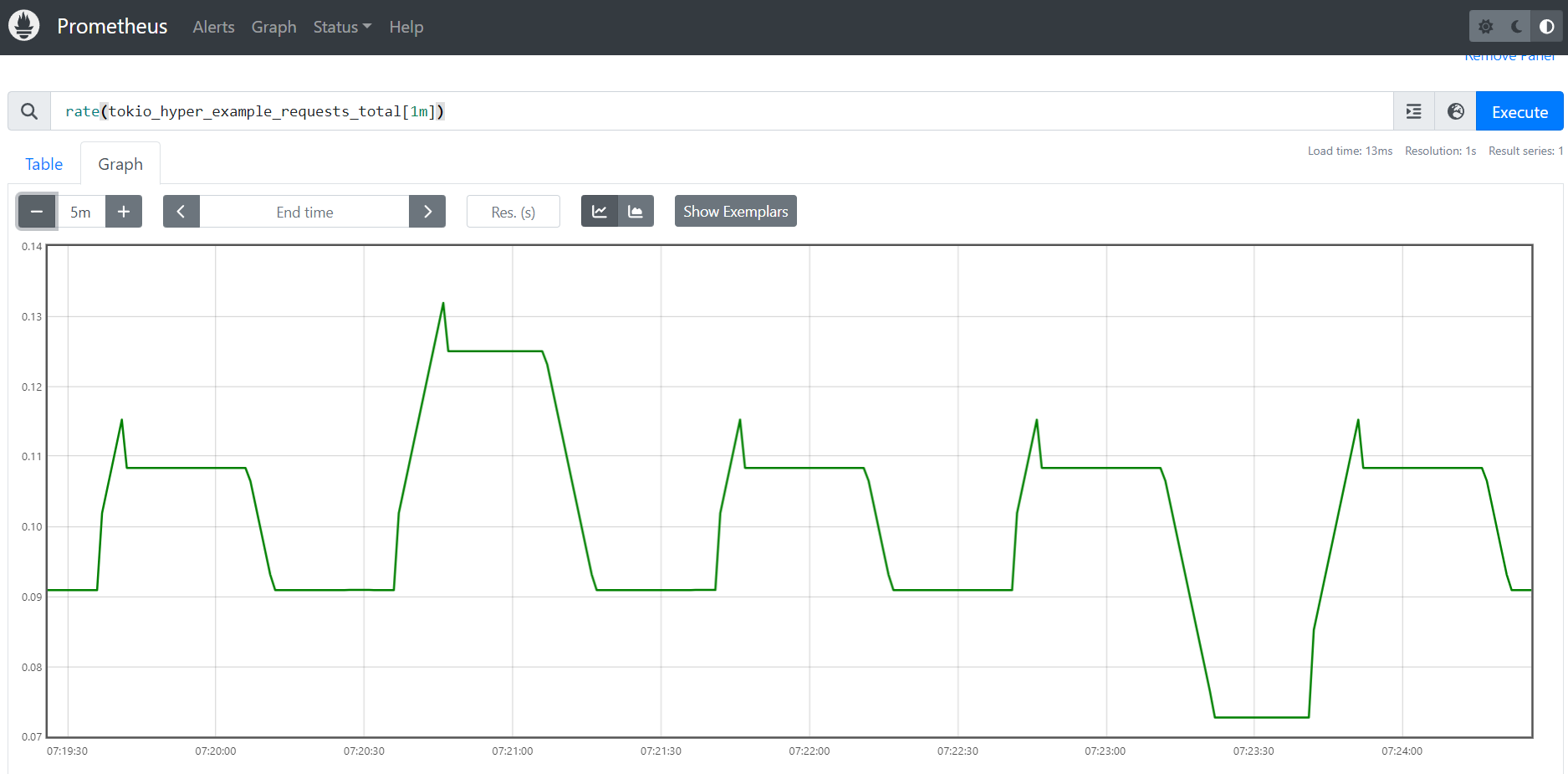
Range Vector rate
The metric is close to the expected 0.1rps but still rounded due to the number of restart.
Datapoints visualization comparison
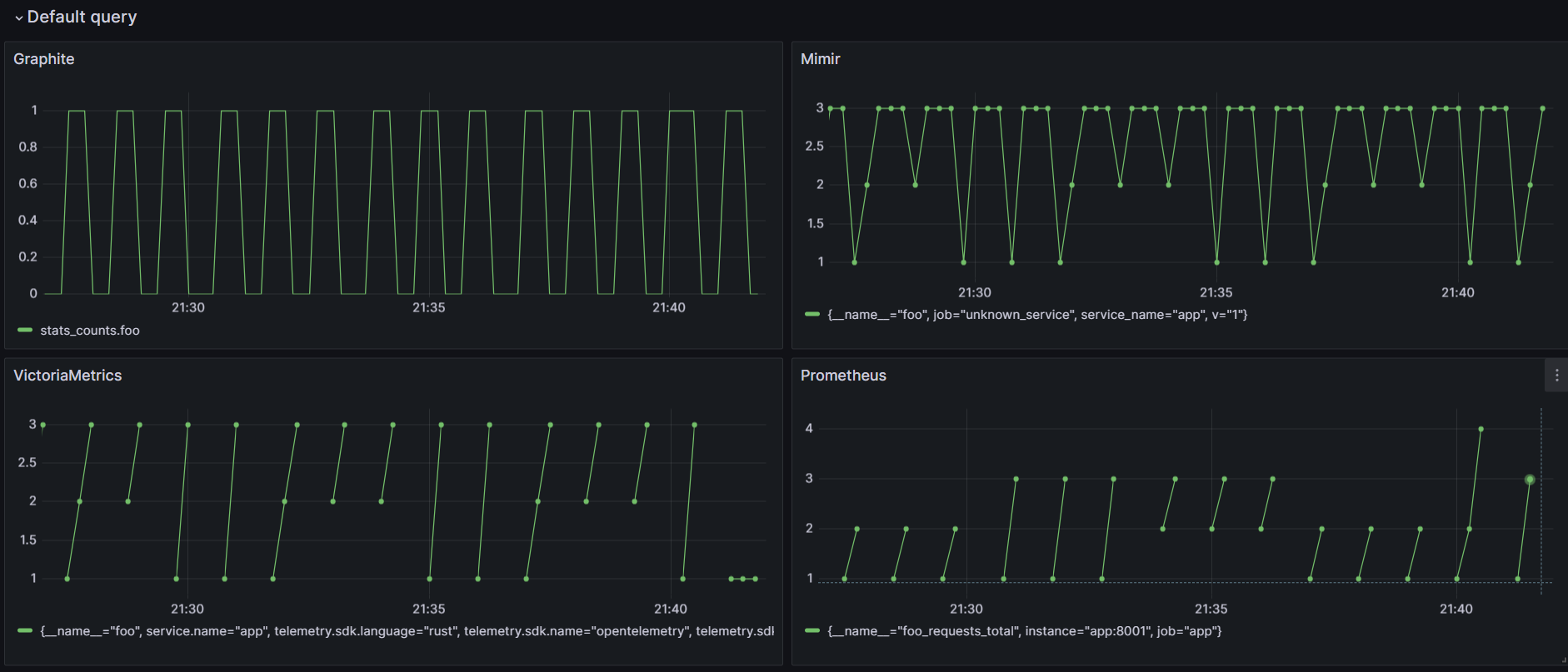
Default Queries
Those graphs show raw metric.
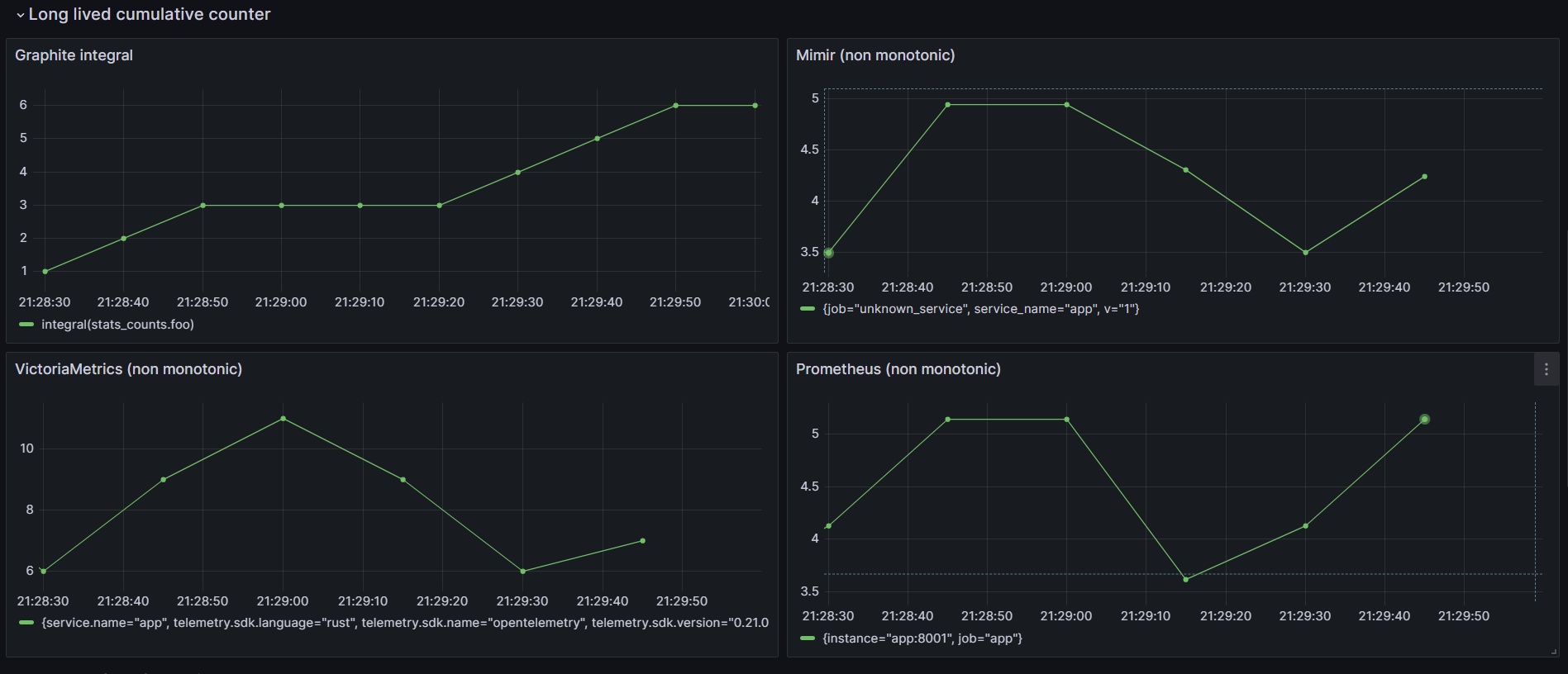
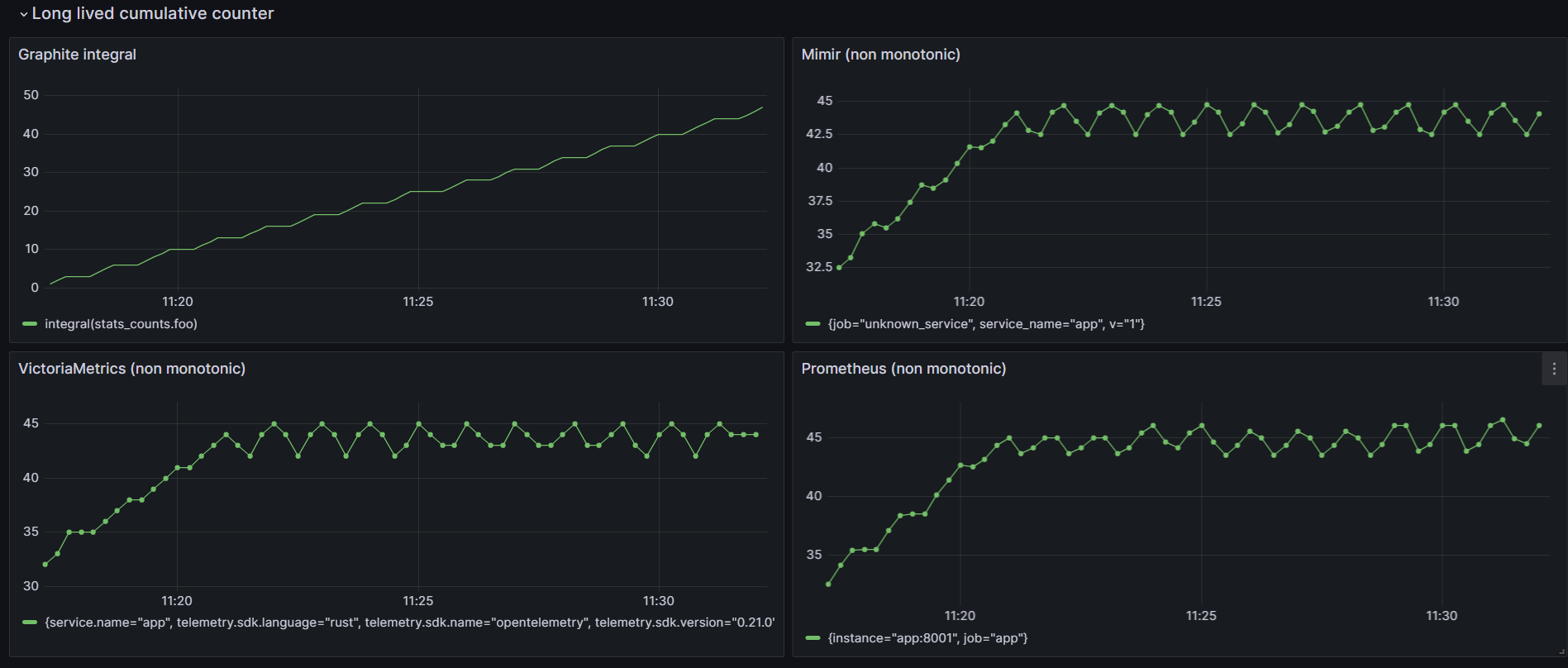
Long lived cumulative counter
Only graphite offers a reliable long lived cumulative counter.
Data can be lost and as mentioned by the prometheus team :
“Prometheus values reliability. You can always view what statistics are available about your system, even under failure conditions. If you need 100% accuracy, such as for per-request billing, Prometheus is not a good choice as the collected data will likely not be detailed and complete enough. In such a case you would be best off using some other system to collect and analyze the data for billing, and Prometheus for the rest of your monitoring.”
Reference :
“Prometheus offers a richer data model and query language, in addition to being easier to run and integrate into your environment. If you want a clustered solution that can hold historical data long term, Graphite may be a better choice.”
Reference:
It seems that supporting such property is a hard topic for cumulative based backend according to Grafana.
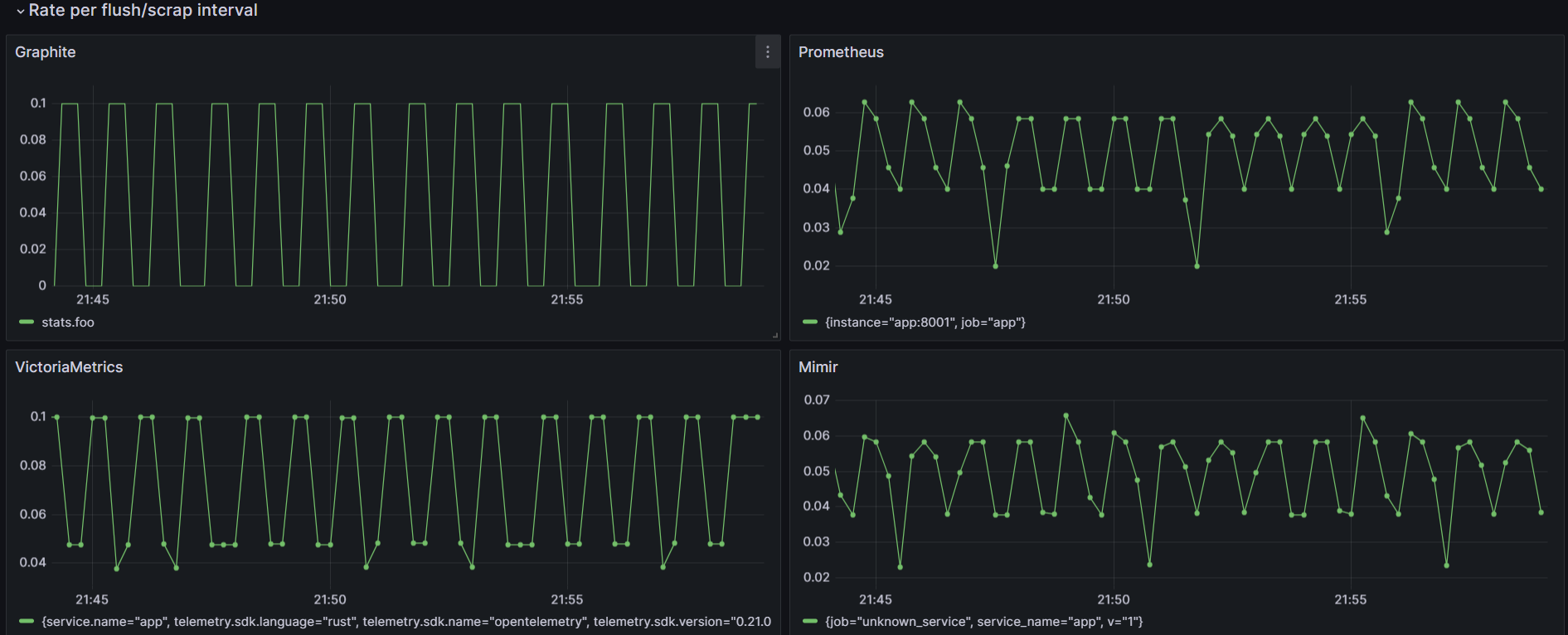
Rates
For observability, rates are really important but it is important to understand how the datapoint can be approximated.
Conclusion
Using rates is the best way to properly view metrics on cumulative/pull based metrics model.
Grafana helps to have an approximated integral (non monotonic) by using : increase(foo[$__range]) increase over a range vector of $__range.
To continue with the main post conclusion